
¿los discos?¿alguna vez sea ha preocupado por esto?
Imagine que va al estadio. El estadio está al lado de una importante avenida por lo que no es problema llegar a el. El estacionamiento es inmenso por lo que no hay problema al estacionarse. Ahora imagine que solo hay 2 salidas en el estacionamiento, Pregunta: ¿Qué sucede al terminar el partido cuando todos quieren salir de ahí?
Por más grande que sea el estacionamiento, por mejores que sean las avenidas, si solo hay 2 salidas todo se atascara al salir. La desesperación cunde, los autos no avanzan y todo está a vuelta de rueda. Por más rápido que los autos puedan conducirse, a muchos kilómetros por hora, por la puerta no pueden salir más autos de los que caben por ahí.
Bueno, pues lo mismo pasa con los discos duros que almacenan la información en un data warehouse. Cada disco tiene cierta capacidad y velocidad para leer los datos. Los discos tienen cierta capacidad de trasmisión de esos datos a la tarjeta controladora de los discos y la tarjeta controladora de los discos a su vez solo pueden pasar al servidor cierta cantidad de datos por segundo al servidor (eso es el ancho de banda).
Uno no puede pedirle que trabajen más rápido o envíen los datos más rápido de lo que pueden hacerlo.
Si diseñamos mal nuestro data warehouse y sobrepasamos esas capacidades, entonces el servidor se se atora, los procesadores se van al 100%, las luces de los discos se encienden y los usuarios se quejan de que todo está lento y no sirve para nada.
Alguna vez se han preguntado si el problema de desempeño está en los discos duros ¿el I/O de datos?
Mucha gente no. Se quejan de que su servidor es lento y se compran otro más grande pero los problemas siguen. Le echan la culpa a la base de datos y cambian de marca. Le echan la culpa a la herramienta y buscan otra. Cambian Windows por Unix. Y cuando tienen un mega servidor, una base de datos carísima y licencias de cuanta herramienta hay disponible en el mercado; todo sigue igual de lento. Entonces, proclaman maldiciones a los 4 vientos y determinan que data warehousing es una basura, que es una falacia, que no sirve para nada, que han tirado miles de dólares a la basura.
Si usted tiene problemas de desempeño con el servidor, antes de pasar por todo esto pregúntese si el almacenamiento está bien diseñado, si la información está bien distribuida en los díscos, si no está sobrepasando los límites de transmisión de datos.
Este problema es mucho más común si tiene SQLServer de Microsoft ya que aunque es una base de datos que se auto-administra de manera admirable uno olvida a veces que con esos gigantescos volúmenes de datos necesita ayuda. En Oracle u otras bases de datos ocurre menos debido a que por la administración que se hace de ella (la base de datos) se le obliga a uno a administrar mejor el almacenamiento. SQLServer tiene muchas de las cosas que Oracle tiene, están ahí, escondidas, solo tiene que investigarlas. Un buen DBA debería detectar estos problemas rápidamente y solucionarlos.
Regresemos al problema del estacionamiento, si ponemos 10 salidas en vez de 2 entonces todo se aligera ¿no? Piense también en que no basta poner 10 salidas, hay que distribuir los autos en el estacionamiento para que al terminar el partido todos tomen una salida diferente. Si tenemos 10 salidas y todos intentan salir por una el problema sigue.
Lo mismo pasará pasar en el servidor.
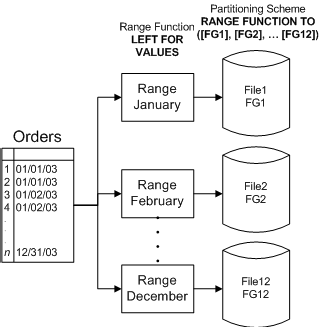
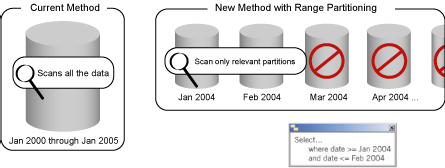
Si ponemos 10 discos duros, el servidor puede escribir o leer 5 gigas de datos más rápido en 10 discos que en uno solo. Pero hay que diseñar la base de datos para que esté distribuida en esos 10 discos de tal forma que al leer lo haga de varios discos a la ves. En SQLServer para eso existen los filegroups que serían los equivalentes de los table spaces de Oracle. También existen las tablas particionadas para que pueda distribuir el contenido de una tabla en varios archivos y estos a su vez en varios discos.
Tenga presente el ejemplo de los autos, repítalo una y otra vez. Si el estacionamiento tiene 10 salidas en vez de dos, uno puede salir más rápido de ahí pero las salidas tienen que estar bien distribuidas y los autos haberse estacionado a lo largo del estacionamiento para que al terminar el partido cada uno de ellos tenga una salida cerca. De esta forma cuando usted piense en datos recuerde distribuir los datos en los diferentes discos duros para que las lecturas puedan distribuirse.
Un amigo compartió conmigo un documento como ejemplo de como pueden ser las cosas. Un disco para los catálogos, discos para la tabla de hechos, discos para la base de datos temporal, etc. Es un ejemplo más que claro de como se logran esos volúmenes gigantescos con determinado hardware.
Por cierto, se supone que los arreglos de discos hacen todo esto en automático pero me duele el hígado cada vez que me lo mencionan. Lo mismo me ocurre cuando me mencionan la palabra SAN. Asegurese de el arreglo o la SAN estén configurados correctamente.
Importante: todo esto no lo exime de usar índices. Tampoco significa que lo óptimo es llenar de discos el servidor. Debe de hacer un análisis para detectar si existen problemas de contención de datos.










Comentarios recientes