
Esta es una de las buenas prácticas que a mi juicio muchas veces se omiten en el diseño de un data warehouse. Las llaves surrogadas o sustitutas son una llave generada artificialmente y que viene a sustituir el campo llave de la dimensión.
Para ponerlo en bits y bytes, lo que hacemos es diseñamos la tabla de tal forma que la llave primara sea un campo con un tipo de dato entero y que además tenga la propiedad «autoincrement» ( o identity, o lo que sea, todo depende de la base de datos utilizada). En la tabla existe un campo que servirá para almacenar la llave original. Al llenar la tabla se generarán valores numéricos que usaremos en vez del campo clave original.
Las ventajas son muchas. Para mí la principal es mejorar el tiempo de respuesta de la base de datos ya que buscar entre números enteros es lo que menos trabajo le cuesta a la base de datos; pero también hay otras, por ejemplo, si estamos juntando en un data warehouse información de sistemas transaccionales diferentes y cada uno de ellos tienen llaves que no se parecen en nada la una de la otro, las llaves surrogadas o sustitutas nos permitirán tener una llave homogénea para ambos sistemas.
Nos permite también resolver cosas como por ejemplo mantener la historia en el tiempo y a la vez separarla. Por ejemplo si queremos que un vendedor que ahora pertenece a otra región, su historia se conserve en el data warehouse en la región original, lo que hacemos es crear un nuevo registro en la tabla de vendedores con una nueva llave sustituta para ese vendedor y usamos esa nueva llave para almacenar las ventas de ese cliente a partir de la fecha que el movimiento ocurre. De esta forma en el data warehouse tendremos las 2 cosas.
| IdVendedor | CveVendedor | Vendedor | Región |
| 2345 | A00X456 | Miguel Gutierrez | Norte |
| … | … | … | |
| 5467 | A00X456 | Miguel Gutierrez | Centro |
Si queremos la historia del vendedor podemos hacer la consulta por el # de Vendedor lo cual abarcará a las 2 llaves (la nueva y la antigua).
select sum(ventas)
from HechosVentas A
join DimVendedores B on a.idVendedor = b.IdVendedor
where b.CveVendedor = ‘A00X456’
Si queremos las ventas de cada región:
select region, sum(ventas)
from HechosVentas A
join DimVendedores B on a.idVendedor = b.IdVendedor
group by region
El modelo por sí solo lo resolverá.

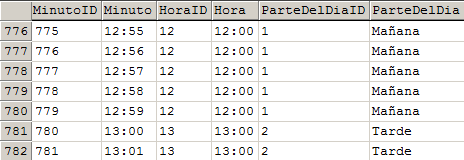
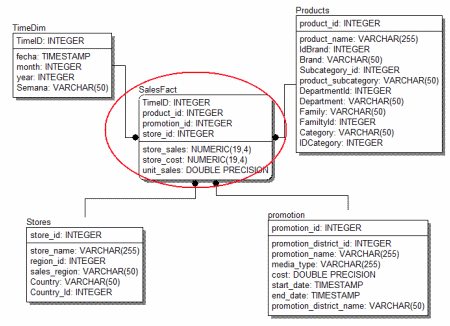
Por cierto, en el modelo arriba mostrado (que no tiene nada que ver con el ejemplo de regiones y vendedores que les daba) pueden ver que yo por ejemplo a todas las llaves usrrogadas las identifico por el sufijo «ID» y para los campos llaves originales reservo todos los campos con el sufijo «cve».
¿implica más trabajo? Si, así es. Muchas veces por falta de tiempo yo en mi caso las omito. También en cierto que hay diferentes maneras de generarlas por ejemplo con algún ETL. Los beneficios son muchos así que cada vez que diseñe un modelo, ponga en la balanza los beneficios que le pueda traer el incluir dichas llaves.
Por cierto, si vá a utilizar el «count distinct» estas llaves sustitutas les vienen como anillo al dedo.



 .
.
 que Excel directamente puede ejecutar Querys sobres bases de datos SQL o Cubos e importarlos directamente a Excel sin necesidad de un intermediario. Hasta te pone un botoncito «actualizar datos». Pero que necesidad…
que Excel directamente puede ejecutar Querys sobres bases de datos SQL o Cubos e importarlos directamente a Excel sin necesidad de un intermediario. Hasta te pone un botoncito «actualizar datos». Pero que necesidad…


{kind=link}
Comentarios recientes